How to Future-Proof Your Digital Infrastructure

In tech, what feels new today can feel old very quickly. So every organization faces the same problem: how do you build digital systems that work well now and still work well later?
The answer is to plan ahead and “future-proof” your digital infrastructure. This is not just about keeping up with trends. It’s about building systems that can adjust, grow, and keep working without constant, expensive rebuilds. It also means building a base strong enough to handle new needs-like AI workloads and more remote work-while staying safe as security threats and budgets change.
For example, as companies deal with fast-growing data, reliable free cloud storage matters a lot, so data stays available and protected even as tools and working habits change.
What Does It Mean to Future-Proof Digital Infrastructure?
Future-proofing digital infrastructure means setting up technology that is flexible, able to scale, and able to recover when things go wrong. The goal is to handle changes in technology, business goals, and user behavior without having to replace everything. You spend now to make systems last longer, so you can add new features and meet new needs without major disruption. This helps businesses stay competitive and keep daily operations fast and secure even as technology changes.
Put simply, future-proofing is planning for things you can’t fully predict. It accepts that digital systems keep shifting, so the infrastructure behind them must handle surprises and support new ideas. This means understanding today’s trends, but more importantly, following design rules that support speed, flexibility, and long-term use-not just quick fixes.
How Is Future-Proofing Different from Modernization?
People often mix up future-proofing and modernization, but they are not the same thing (even though they work well together). Modernization usually means updating older systems to current standards. It reduces technical debt, improves speed, and improves security in what you already have. It’s like fixing up an old house so it meets today’s safety rules and comfort levels.
Future-proofing is more about planning ahead. It’s like building or redesigning the house so it can handle changes later-like adding new rooms, using new energy options, or installing smart devices that don’t exist yet.
With future-proofing, you design for easy change from the start. So if technologies like quantum computing or advanced AI become common, your setup can add them without another major rebuild. It’s the difference between patching a roof leak and building a roof that can support solar panels and handle extreme weather for years.
Core Components of Digital Infrastructure
Digital infrastructure is the connected set of hardware, software, and services that run an organization’s digital work. Knowing the main parts is the first step to future-proofing. Common parts include data centers (physical or virtual), which store, manage, and process large amounts of data. They contain servers, storage, and network equipment that provide the computing power needed for apps and data.
Many organizations also use public cloud services, which provide computing resources over the internet. These include Infrastructure as a Service (IaaS), Platform as a Service (PaaS), and Software as a Service (SaaS). They let businesses scale without buying lots of hardware upfront, and they support remote access.
Networking equipment (routers, switches, and communication rules) moves data between systems, users, and apps. Security tools like firewalls, intrusion detection, and encryption should be built through all layers to protect data and privacy.
Lastly, data management and storage tools (databases, storage servers, and backup systems) keep data organized and easy to retrieve for reporting and decision-making.
Why Businesses Invest in Future-Proof Infrastructure
Businesses invest in future-proof infrastructure because it supports long-term success in an unstable market. Old systems reduce productivity, raise costs, and create security risks. A future-proof setup helps businesses control spending by using scalable services (often cloud-based) so they pay for what they use. Over time, this improves budget planning and cuts operating waste.
It also supports competition. Digital progress often moves as fast as your infrastructure allows. Companies that build for efficiency and stability early can adopt new tools faster, add AI and IoT with fewer roadblocks, and avoid hard limits that slow down product plans. With the right base, innovation is supported instead of blocked.
Why Future-Proofing Your Digital Infrastructure Matters
The need for future-proof infrastructure is stronger than ever. Technology keeps changing, and digital demand keeps rising. Whether an organization can adjust and grow depends directly on how strong and flexible its IT foundation is. This is no longer only about improvement-it’s about staying in business and growing steadily.
Staying Competitive Amid Evolving Technology
New technologies arrive constantly: AI, blockchain, AR/VR, and even quantum computing. A future-proof infrastructure can add these tools without needing to rebuild everything. That flexibility helps businesses stay competitive, because they can use new tech to improve products, services, and internal work faster than competitors stuck on rigid older systems.
AI is a good example. Automation and predictive analytics require strong computing, large storage, and low-delay networks. Organizations with scalable infrastructure can use cloud systems that handle heavy machine learning workloads. This way, innovation is not limited by the physical setup behind the software.
Reducing Long-Term Operational Costs
Future-proofing can look expensive at the start, but it usually saves money over time. Quick fixes often add technical debt, which leads to costly rework, more maintenance, and more downtime. A well-planned infrastructure reduces the need for major rebuilds and avoids many hidden costs.
Scalable systems let businesses handle more users, more data, and more apps without replacing major parts. This lowers cost by improving how resources are used-especially in cloud models where you pay based on usage. Automation also reduces repetitive manual work and mistakes, so IT teams can focus on higher-value tasks and keep costs down.
Mitigating Cybersecurity Risks
Security threats keep changing and getting smarter. Older infrastructure often lacks patches and modern protections, making it easier to attack. Future-proofing includes building security in from the start, using layered defenses like advanced threat detection, Multi-Factor Authentication (MFA), and regular security checks.
A strong security approach, including zero-trust, is required for modern systems. Zero-trust means every user and device must prove who they are each time they request access, no matter where they are. This reduces the risk of unauthorized access and data leaks. Fixing weak points early protects sensitive data, supports legal requirements, and helps maintain customer trust.
Ensuring Regulatory Compliance
Data privacy rules and industry regulations keep getting stricter. Staying compliant is ongoing work. If you fail, the results can include fines, lawsuits, and loss of trust. A future-proof infrastructure treats compliance and data governance as core design goals, not last-minute add-ons.
Strong data governance policies protect data quality and security, and help meet rules like GDPR and HIPAA. Clear standards and less unnecessary data movement also reduce wasted computing power. When rules change, organizations with good governance can respond faster and with less risk.
Supporting Business Continuity and Disaster Recovery
Disruptions happen: cyberattacks, storms, outages, and hardware failures. Without strong backup and recovery, organizations can lose data, face long downtime, and damage their reputation. Future-proofing requires plans that restore data quickly and keep operations running.
This includes automatic backups stored in multiple regions, regular testing of recovery plans, and cloud backups to speed up recovery. Spreading workloads across multiple systems also reduces downtime risk. A good disaster recovery plan includes clear recovery time objectives (RTOs) and recovery point objectives (RPOs), so teams know what must come back first and how fast.
Key Principles for Future-Proofing Digital Infrastructure
Infrastructure that lasts is built on a few key principles. These are not just technical details-they are guiding ideas that shape design, rollout, and day-to-day management so flexibility and resilience are built in.
Scalability to Meet Changing Demands
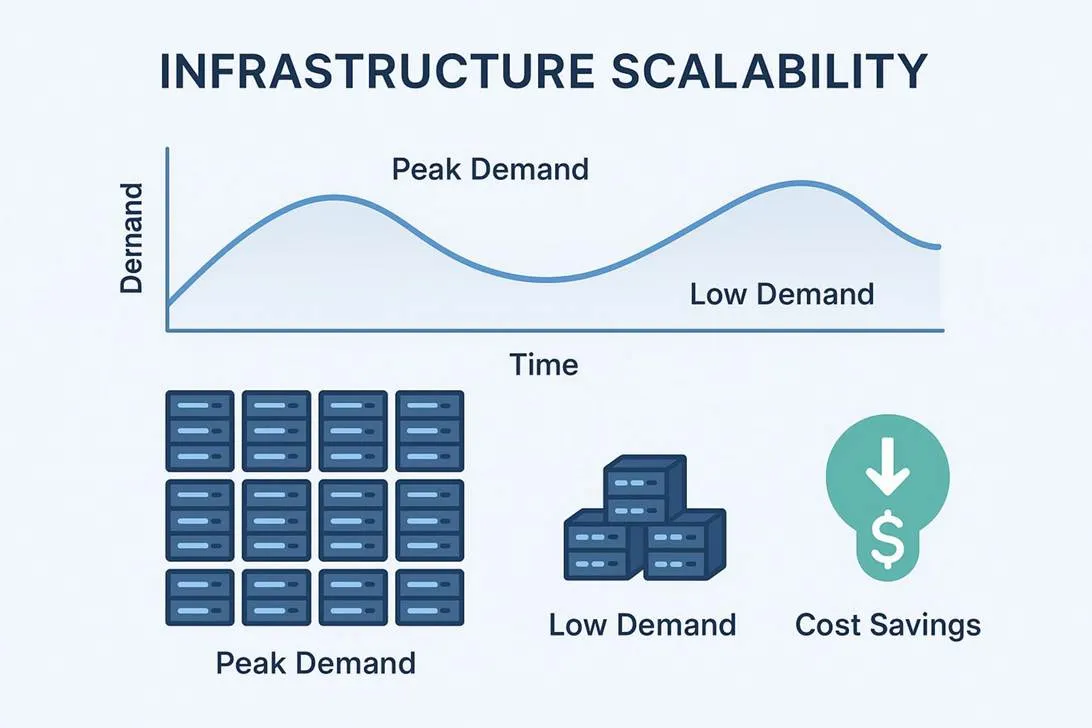
Scalability is a core idea of future-proofing. It means your infrastructure can grow or shrink as demand changes, without needing a full redesign. Whether you need to support more customers, add new apps, or store more data, scalable infrastructure keeps things running smoothly.
Virtualization and cloud computing are common ways to scale. Virtual machines and containers use resources more efficiently, and cloud platforms can scale on demand. During peak times (like holiday sales), companies can raise capacity quickly to avoid outages. When demand drops, they can reduce capacity and save money. Fast networking and tools like software-defined networking (SDN) also help keep systems ready for future growth.
Modularity and Interoperability in System design
Modularity and interoperability help systems stay flexible. Modular designs, such as microservices, break large apps into smaller parts that can be updated or scaled on their own. This reduces risk because you can change one part without breaking everything.
Interoperability means different parts and systems can work together. Standard APIs and open protocols help prevent getting stuck with one vendor and make it easier to add new tools later. When systems can be swapped or extended easily, companies can move faster and adopt better solutions without heavy custom work.
Standardization to Avoid Vendor Lock-In
Standardization helps avoid vendor lock-in, where a business becomes dependent on one provider’s tools and pricing. If your systems rely too heavily on proprietary tech, moving away later can be expensive and difficult. This reduces choice and bargaining power.
Using open standards, open-source software, and common protocols improves portability and compatibility. It also supports cloud choices like hybrid and multi-cloud, where workloads are spread across providers. This reduces risk and keeps options open for the future.
Continuous Monitoring and Automated Optimization
Infrastructure stays future-proof only if it can keep adjusting over time. That requires ongoing monitoring and automated improvements. Watching key metrics-CPU, memory, storage, network use, app response times, and security events-helps spot issues before users notice. Tools like the ELK stack or Splunk collect and show logs so teams can see what’s happening in real time.
Automation is also important. AIOps uses AI and machine learning to spot unusual behavior, find root causes, and suggest or apply fixes. Predictive maintenance uses past data to predict hardware problems, reducing surprise outages. Automation can also tune settings and resource use so performance stays high without constant manual effort.
Flexibility with Hybrid and Multi-Cloud Approaches
Most organizations can’t use one single setup for everything. Hybrid and multi-cloud approaches add flexibility. Hybrid combines on-premises and cloud, so sensitive systems can stay local while other workloads use cloud scaling and cost benefits.
Multi-cloud uses more than one public cloud provider. It improves redundancy, reduces vendor lock-in, and lets organizations pick the best service for each need (cost, speed, compliance). Spreading workloads across different environments builds resilience and supports long-term growth.
How to Build a Resilient and Adaptable Infrastructure
Building infrastructure that lasts is more than installing tools. It requires a full approach that builds resilience and flexibility into every layer. That means planning for continuity, efficiency, and smart data handling from day one.
Ways to Design for Portability and High Availability
Portability and high availability help systems keep working during change or failure. Portability means you can move apps and data between environments (on-premises, private cloud, public cloud) without major rewrites. Containers like Docker and orchestration tools like Kubernetes help by packaging apps with what they need to run, so they work consistently across platforms. Portability also means using open standards and APIs instead of depending deeply on one vendor’s special services.
High availability means reducing downtime. Common methods include load balancers, fault-tolerant designs, and redundant systems in different locations. For example, don’t place all AI or cloud workloads in one region; design so services can move and keep scaling even if one location has issues. Distributed systems that can recover automatically help organizations reach very high uptime.
Energy Efficiency and Sustainable Practices
Demand for energy is rising fast due to AI, cloud, and digital services. Data centers and power grids are struggling to keep up. That makes energy efficiency part of future-proofing, not just an environmental goal. The old idea of unlimited power and space is no longer realistic. Now, good design must care about “performance per watt” along with “performance per dollar.”
Strong companies treat power and grid capacity like a real product dependency. That means optimizing workloads, using smaller deployments where possible, and placing workloads in regions based on power limits and costs.
Edge computing can also help by processing data closer to where it is created, reducing the need for huge centralized data centers. When infrastructure is treated as limited, optimization becomes the main way to keep innovation moving without hitting physical limits.
Disaster Recovery and Backup Strategies
Resilient infrastructure can recover quickly after unexpected events. That makes disaster recovery (DR) and backups a must. Without them, businesses risk data loss, long outages, and major reputation damage. Future-proofing requires plans that restore operations quickly and limit downtime.
Main parts include automatic backups stored in more than one region, frequent DR testing to find weak spots, and cloud backup options for speed and flexibility. Plans should set clear RTOs and RPOs so teams know what “acceptable recovery” looks like. Regular drills with all needed staff help people respond calmly and correctly during real incidents.
Data Governance and Lifecycle Management
Data powers modern business, so data governance and lifecycle management are key for infrastructure that lasts. Governance is more than compliance work-it helps keep data accurate, safe, and usable over time. This includes rules for collecting, storing, processing, using, and archiving data, so data stays protected and easy to access.
Clear data standards and less duplicated data movement can free up computing resources and reduce costs. Lifecycle management also means keeping data only as long as needed, then deleting it safely when it is no longer required. This reduces risk, supports better decisions, keeps customer trust, and uses storage and compute more efficiently.
Best Practices and Technology Choices
Building strong digital infrastructure requires smart choices and solid practices. The goal is to use the right tools and methods to build systems that work well now and can handle what comes next.
Embracing Cloud Computing and Hybrid Solutions
Cloud computing-often using hybrid or multi-cloud setups-is a major part of future-proofing. Cloud services provide scaling, flexibility, and cost control. Moving data and apps to cloud platforms lets organizations adjust resources as needs change without large upfront hardware spending.
Hybrid cloud is often a good balance: keep sensitive systems on-premises while using the cloud for other workloads. Multi-cloud adds more flexibility by using more than one provider, reducing vendor lock-in and improving redundancy. Cloud providers also offer regular updates, built-in redundancy, and security features that support continuity.
Implementing Automation and Infrastructure as Code
Automation helps manage infrastructure with fewer mistakes and less manual work. Infrastructure as Code (IaC) is a key part of this. With IaC, you define infrastructure in files, not manual setup steps. Teams can use version control, testing, and shared workflows, which improves consistency across environments.
Tools like Terraform, Ansible, Puppet, and Chef define the “desired state” of infrastructure. This reduces human error, supports faster deployments, and helps avoid configuration drift. CI/CD pipelines also help by automating testing and deployment. Automated monitoring and alerts reduce time spent on routine tasks, so teams can focus on bigger improvements.
Leveraging AI and AIOps for Infrastructure Management
AIOps is changing infrastructure management by shifting from “fix it when it breaks” to “spot it early and prevent it.” It uses machine learning and analytics to detect unusual patterns, find root causes, and suggest or apply fixes. As infrastructure gets more complex, manual oversight becomes unrealistic.
Predictive maintenance is a strong example: by analyzing past data, AIOps can predict failures and reduce surprise downtime. It also helps with capacity planning by showing trends and predicting future needs. This supports better scaling decisions and better resource use. The move away from brute-force thinking and toward efficient, well-managed systems helps keep infrastructure stable and secure.
Adopting Zero-Trust Security Models
As threats keep changing and the traditional “office network perimeter” has faded, zero-trust is a practical security model for long-term protection. Zero-trust means “never trust, always verify.” Every user and device must prove identity before accessing resources, no matter where they are.
Common parts include MFA, Role-Based Access Control (RBAC), and network segmentation to limit damage if an attacker gets in. Continuous monitoring helps detect threats quickly. With zero-trust, organizations build a security setup that can handle new types of attacks and protect critical operations.
Regular Technology Updates and Lifecycle Planning
Technology keeps moving, so regular updates and lifecycle planning are necessary. Old systems slow work, cost more, and increase security risk. Regular reviews help keep infrastructure aligned with business needs and make it easier to add newer tools and remove waste.
This includes scheduled reviews, removing unused resources, controlling costs, and keeping software and hardware updated. Lifecycle planning also means tracking end-of-life timelines, budgeting replacements, and planning changeovers so there is less disruption. This helps organizations avoid falling behind and keeps systems secure and efficient.
Assessing and Improving Your Current Digital Infrastructure
Before you start future-proofing, you need a clear view of what you already have-what works, what doesn’t, and where the risk is. This baseline helps you make better choices and focus on changes that matter most.
How to Evaluate Infrastructure Readiness for Future Demands
To evaluate readiness, start with a complete inventory of hardware, software, and network components. Identify performance bottlenecks and single points of failure that could take systems down. Next, check whether current systems can scale: can they support more users, more data, and more apps without major strain?
A helpful approach is to review five areas:
● Operational: performance, reliability, user experience
● Security: access control, data protection, vulnerability handling
● Compliance: rules like GDPR, HIPAA, and industry standards
● Financial: maintenance costs, licensing, support
● Future-readiness: ability to grow and adopt new technology
With clear data in these areas, organizations can decide what needs action now and what investments will pay off over time.
Key Metrics for Performance, Reliability, and Security
Useful metrics help teams improve systems with real data. For performance, track CPU, memory, and disk use; network bandwidth and latency; app response times; and database query speed. These point to bottlenecks and inefficiency.
For reliability, focus on uptime, SLA performance, outage frequency, and mean time to repair (MTTR). For security, monitor suspicious activity, failed logins, malware events, and signs of data theft. Bringing these signals into one place (often with AIOps tools) helps teams spot patterns, respond faster, and keep infrastructure healthy.
Steps to Start Future-Proofing Your Digital Infrastructure
Starting can feel overwhelming, but it gets easier when you break the work into clear steps. The goal is to build a strong base and keep improving over time.
Prioritizing High-Impact Initiatives
Start by picking initiatives that have the biggest effect on business goals and are realistic given your limits. You can’t replace everything at once, and you shouldn’t try. Focus on work that reduces major risk or creates clear value.
When choosing priorities, weigh:
● Business impact: revenue, cost savings, customer experience
● Urgency: security holes, compliance gaps, failure risk
● Effort and disruption: time, skills needed, downtime risk
● Dependencies: work that must happen before other improvements
For example, replacing aging hardware with known security weaknesses may be more urgent than improving a low-use internal tool.
Creating a Roadmap for Phased Modernization
After choosing priorities, build a roadmap that rolls changes out in phases. The plan should include timelines, milestones, and success measures over months and years. Future-proofing is ongoing work, so phased delivery helps you learn and adjust without disrupting everything.
A roadmap might include gradual cloud migration, staged network upgrades, or rolling out zero-trust in steps. It should also explain how new tools will connect to existing systems. Share the roadmap with stakeholders so they understand the plan and support it. Involving them early improves alignment and reduces surprises later.
Developing Governance and Accountability Structures
Clear governance keeps future-proofing work on track. Without defined roles and decision paths, plans often stall. Set up rules for who makes decisions, how issues are escalated, and how progress is tracked.
Define responsibilities for admins, network engineers, security staff, and others so work is coordinated and not duplicated. Governance should also include how IT works with other departments, so infrastructure decisions support real business needs. A culture where teams share ideas and take ownership makes the infrastructure easier to improve over time.
Common Challenges and How to Overcome Them
Future-proofing is rarely simple. Common issues include limited budgets, older systems, and gaps in staff skills. Knowing these problems ahead of time makes it easier to plan around them.
Balancing Cost with Future Needs
A common problem is choosing between spending now and saving for later. Leaders often feel pressure to cut short-term spending, which can delay needed upgrades. Over time, this usually increases technical debt, raises operating costs, and increases the chance of outages or breaches.
To handle this, build a business case with clear ROI. Show savings from less downtime, better efficiency, stronger security, and faster adoption of revenue-driving tools. A phased roadmap spreads cost over time. Usage-based cloud pricing can also reduce upfront spending and match costs to real demand.
Managing Technical Debt and Legacy Systems
Technical debt and legacy systems often block progress. Older systems may still work, but they are hard to scale, hard to connect to modern tools, and often less secure. Replacing them can feel too expensive or risky, which leads many teams to keep patching instead.
A better approach is to assess which legacy systems create the highest risk or slow down work the most, then prioritize those. Hybrid setups can help you move workloads in steps while keeping operations running. Virtualization and containerization can wrap older apps so they are easier to run and move. API-based integration can also connect old and new systems without replacing everything at once.
Training and Upskilling IT Teams
New tools require new skills. If teams aren’t trained, rollouts slow down, systems get managed poorly, and improvement opportunities are missed. This is especially true for cloud design, automation, security, and AIOps.
Organizations should fund ongoing training and certifications, and support learning in areas like cloud, hybrid setups, security, and automation. A FinOps team can help manage cloud costs and usage. Mentoring and cross-team projects also help spread knowledge. Skilled teams are one of the strongest supports for long-term infrastructure success.
Aligning Digital Infrastructure Strategy with Business Goals
Even a strong technical plan fails if it doesn’t support the business. IT can become isolated and choose tools that don’t match real goals. That leads to spending without clear value and slows wider digital change.
Fixing this requires close work between IT and business leaders. Map business processes to IT systems so changes in one don’t break the other. Keep regular check-ins and feedback loops so infrastructure work supports goals like customer experience, efficiency, and new products. When infrastructure is treated as a real product decision, it becomes a business driver, not just a cost.
What to Look for in a Technology Partner or Service Provider
Many organizations bring in outside experts for modernization and future-proofing. Picking the right partner can strongly affect how successful and long-lasting your infrastructure will be.
Expertise in Emerging Technologies
A strong partner should understand emerging technologies that shape infrastructure: cloud, AI/ML, IoT, edge computing, and modern security. More importantly, they should know how to apply these tools to real business problems, not just talk about trends. They should also understand practical limits like power and grid capacity, and how to build efficient systems that work within those limits.
Look for proof they have delivered similar work before. They should explain benefits and risks clearly, show how new tools fit with your current setup, and recommend solutions that make sense for your needs.
Track Record for Delivering Scalable Solutions
A partner should have real experience building systems that scale. That includes cloud architectures that grow with demand, modular designs that expand easily, and networks that handle more traffic and data over time.
Ask for case studies and references. Ask how they evaluate current systems, build roadmaps, and deliver projects in phases. A reliable partner can point to measurable results, like reduced costs, improved performance, stronger security, and fewer outages.
Support for Ongoing Maintenance and Optimization
Future-proofing is ongoing work, so partners should support long-term operations too. This can include monitoring, health checks, patching, and 24/7 support. They should also look for ways to improve performance and help you adopt new tech over time.
Good partners also help train internal teams, so you’re not dependent on outside help for everything. They should provide guidance on using automation, AIOps, and compliance processes, acting like an extension of your team.
Maintaining a Culture of Continuous Improvement
Technology keeps changing, and organizations must change with it. Future-proofing is not a finish line. It depends on building a habit of ongoing improvement across the organization, not just buying new tools.
Promoting Collaboration Across Teams
Working in silos slows down infrastructure improvement. To keep systems flexible and stable, development, operations, security, and business teams need to work together. DevOps is one common way to do this by sharing responsibility and speeding up delivery.
Support collaboration with clear communication channels, shared learning sessions, and cross-team projects. When developers understand operations and operations understand development goals, systems are built with fewer mistakes and fewer future problems. Bringing business stakeholders into planning also helps keep work aligned with real priorities.
Encouraging Innovation and Regular Review Cycles
Ongoing improvement depends on teams being able to test ideas and learn. This does not mean adopting every trend. It means giving teams room to experiment, measure results, and improve without fear of blame when something doesn’t work.
Regular review cycles keep innovation grounded. These reviews check performance, security, cost, and relevance against goals and benchmarks. Monitoring devices (including basic equipment) through IoT tools can also help find issues early. Reviews help teams spot what should be upgraded, moved, resized, or removed. By tracking metrics, getting stakeholder feedback, and watching new trends, organizations can keep infrastructure efficient and ready for change.
Future Trends Impacting Digital Infrastructure
Digital infrastructure is shaped by new trends. Understanding what’s coming helps organizations build systems that can handle new demands and new limits.
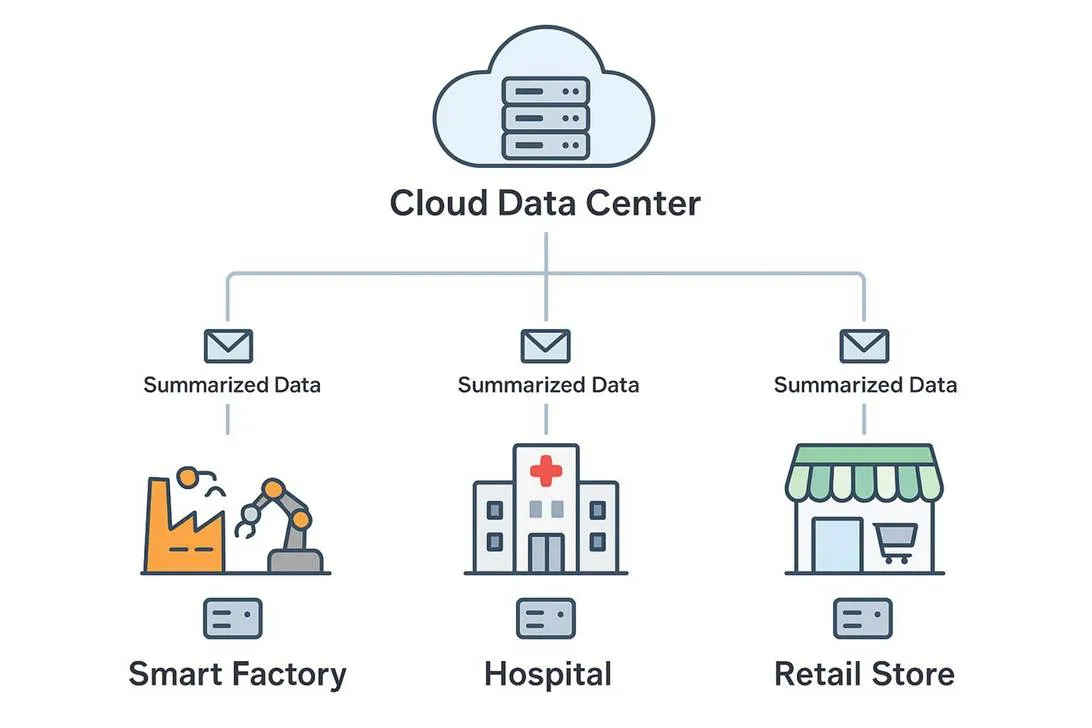
Increasing Importance of Edge Computing
Edge computing is becoming a key part of modern infrastructure. As IoT grows and AI needs real-time responses, processing data closer to where it is created reduces delay and reduces pressure on central data centers. It also reduces the amount of data that must travel back and forth to the cloud.
By bringing computing closer to users and devices, edge computing can improve privacy, improve efficiency, and reduce cloud bottlenecks. It also makes use of powerful devices people already have. For places like universities, edge computing may become more important as users and devices move on and off campus, changing network demand constantly.
The Role of AI and Machine Learning in Infrastructure
AI and ML are becoming part of infrastructure management, not just apps running on top. AI demand is increasing pressure on data centers and power systems, so organizations must plan around real physical limits, not just software goals.
AI also powers AIOps tools that automate monitoring, detect problems, and guide fixes. It supports predictive maintenance, capacity planning, and smarter resource use, including better “performance per watt.” Small language models (SLMs) also offer a way to run useful AI with less dependence on massive data centers, helping organizations focus on efficiency instead of brute force.
Growing Focus on Energy, Sustainability, and Regulatory Changes
Energy, sustainability, and regulation will shape infrastructure decisions more each year. As AI and digital services drive higher power use, grid capacity becomes a major limit. Companies are not only buying chips-they are also competing for access to electricity and data center capacity. Leaders who plan for power availability early will move faster than those waiting for utility connections.
At the same time, environmental pressure and new rules are increasing. Organizations need energy-efficient designs and strong data governance to meet changing requirements and reduce risk. Infrastructure plans must treat power limits and grid access as real constraints, because this is becoming normal for modern innovation.
Conclusion
Future-proofing digital infrastructure is ongoing work. It’s a cycle of learning, adjusting, and improving. It also requires a shift in mindset: moving away from “bigger is better” and focusing more on efficiency-first design. Power and space are no longer unlimited, and progress often depends on practical infrastructure limits.
Technology leaders now need to treat energy, cooling, and grid access as real strategic factors. Future-ready systems focus on doing more with less: optimized architectures, small language models, edge computing, and energy-aware code. When infrastructure is treated as a limited resource, optimization becomes the main driver of sustainable innovation. The organizations that plan early for resilience and flexibility will be the ones that build digital systems that last.